Efter nogle måneders arbejde med at behandle allerede eksisterende data og indhente mere data fra kendte og nye kilder, har vi nu sat anden version af vores model til at forudsige vedligeholdelsesomkostninger i produktion. Modellen bliver brugt til at estimere vedligeholdelsesomkostninger på bygningsdele, når man opretter en vedligeholdelsesplan i appen.
Hvorfor en ny model?
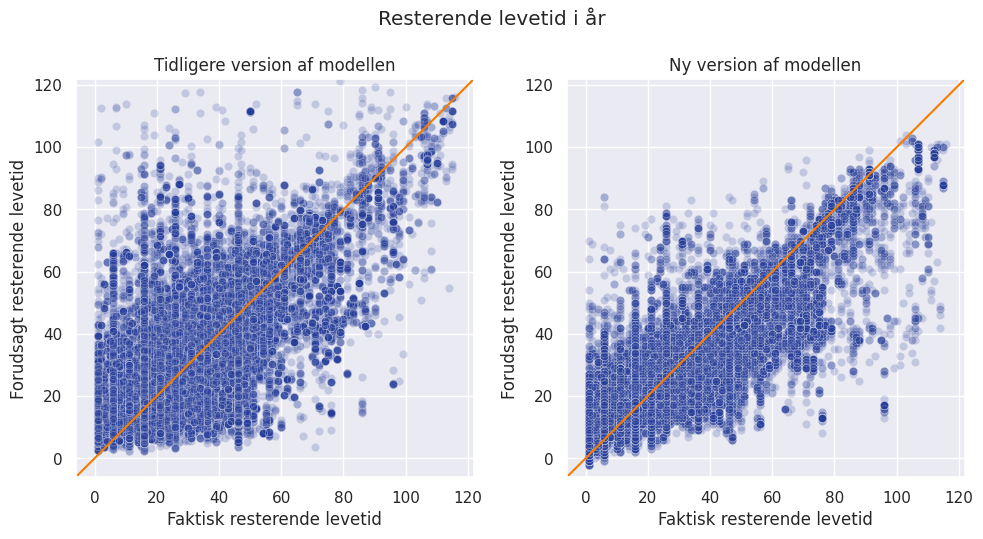
Den største forskel på den nye og den tidligere version af modellen er, at vi nu har meget mere data, hvilket har gjort det muligt at lave en model, der er mere robust og bedre til at generalisere til nye ejendomme, og som kan give forudsigelser på et mere detaljeret niveau. Den tidligere version af modellen kunne forudsige vedligeholdelsesomkostninger for en hel ejendom/afdeling, dvs. en samling af bygninger, hvorefter der blev brugt en fast gns. fordeling af omkostninger ud på bygningsdele til at forudsige vedligeholdelsesomkostninger for de enkelte bygningsdele under ejendommen. Den nye version af modellen forudsiger vedligeholdelsesomkostninger helt nede på bygningsdelsniveau, og på den enkelte bygning under en ejendom i stedet for hele ejendommen samlet.
At det nu kan lade sig gøre, skyldes følgende ting:
- Den nye version af modellen er trænet på 336.487 flere unikke bygningsdele under 801 flere ejendomme end den tidligere version.
- Landsbyggefonden indsamler vedligeholdelsesomkostninger på bygningsdelsniveau, som er forudsagt af eksterne rådgivere for de almene boligselskaber. Den tidligere version af modellen var udelukkende trænet på disse vedligeholdelsesomkostninger. I den nye version bruger vi vedligeholdelsesomkostningerne fra vores kunders egne interne vedligeholdelsesplaner som udgangspunkt, og supplerer med omkostninger fra de eksterne granskninger for bygningsdele med manglende omkostninger fra vores kunder. I fremtiden vil vi også bruge vedligeholdelsesomkostninger, som er indtastet i appen, så vi får træningsdata fra et bredere udsnit af vores kunder.
Mængden af informationer, som bliver brugt som input til modellen, når den skal lave forudsigelser, er også vokset betydeligt. Den tidligere version af modellen brugte udelukkende følgende information om en ejendom fra BBR: Antal kvm. bygning, samlet bebygget areal, mest udbredte facademateriale, og tidligste renoveringsår af en bygning under ejendommen. Den nye version af modellen bruger følgende informationer fra følgende kilder:
- Vores kunders vedligeholdelsesplaner: Bygningsdeles mængder, materialer, installationsår og resterende levetid.
- Landsbyggefondens kalkulationsark: Bygningsdeles mængder, materialer, installationsår og resterende levetid.
- levetidstabeller.dk (BUILD – Aalborg Universitet): Gns. levetid for bygningsdele baseret på materiale.
- Danmarks Statistik: Areal af- og befolkningstæthed i kommuner, postdistrikter og postnumre.
- Energistyrelsen: Bygningers energimærke.
- BBR: Bygningers antal kvm. (samlet og fordelt på bolig og erhverv og bebygget areal), anvendelse, opførsels- og renoveringsår, tag- og facadematerialer og type af vandtilførsel, afløb og varmeinstallation.
Præcision på ejendomsniveau
I data fra henholdsvis vores kunders egne budgetter og de granskninger, som er lavet af eksterne leverandører, kan man se, at de estimerede vedligeholdelsesomkostninger for de enkelte bygningsdele under en bygning kan variere meget, da det er en subjektiv vurdering som afhænger af, hvem der laver den. Det kommer også til udtryk i grafen herunder, som sammenligner de forudsagte- og faktiske vedligeholdelsesomkostninger på bygningsdelsniveau på bygningsniveau fra den nye version af modellen. For en model, som altid gætter 100% korrekt, vil alle punkterne ligge på den diagonale linje, og i grafen kan man se, at der især for bygningsdele med vedligeholdelsesomkostninger i den lave ende kan være ret store udsving i, hvor tæt modellens forudsigelser er på de faktiske omkostninger.

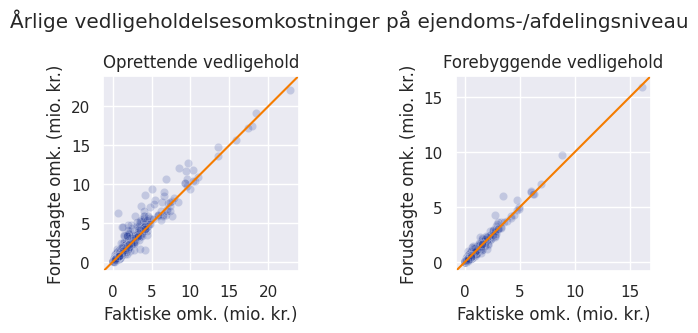
Hvis man til gengæld summerer omkostningerne for alle bygningsdele under alle bygninger under en ejendom/afdeling, så man får de samlede omkostninger for hele ejendommen/afdelingen, så er der større konsensus på tværs af kilder, hvilket også kommer til udtryk i grafen herunder, som viser samme forhold som på grafen ovenover, blot på ejendoms-/afdelingsniveau. Her kan man se, at de forudsagte vedligeholdelsesomkostninger på ejendoms-/afdelingsniveau ligger meget tæt på de faktiske omkostninger.

R2 er en statistik måling, som bruges til at vurdere, hvor god en model er til at lave forudsigelser. Tallet ligger mellem 0 og 1, og en model, der altid gætter korrekt, vil have en R2 på 1. Den nye version af modellen har en R2 på 0,8, når den testes på nye ejendomme på bygningsdelsniveau på bygningsniveau for både oprettende og forebyggende vedligehold. Dvs. at 80% af variationen i vedligeholdelsesomkostninger kan forklares af variationen i inputparametrene (BBR-oplysninger, mængde, materiale osv.). På afdelingniveau kommer R2 op på 0,88 for oprettende vedligehold og 0,96 for forebyggende.
Vi er glade for at kunne tilbyde forbedrede vedligeholdelsesestimater og er spændte på at få tilbagemeldinger fra vores kunder. Og så har vi en masse idéer til, hvordan estimaterne kan blive endnu bedre, bl.a. ved at inddrage informationer om fredede ejendomme og afstanden til nærmeste kystlinje.